
mapreduce简介
MapReduce是一个编程模型,用于处理和生成大数据。用户通过编写Map函数处理输入键值对生成中间键值对,通过编写Reduce函数来合并所有的中间键值对并生成结果。在我们的日常生活中,大部分的任务都可以被抽象成一个MapReduce模型,并通过这个模型解决问题。
MapReduce介绍
我们所遇到的大多数计算问题都很直观,但是当计算的数量十分庞大时,我们往往要借助于成百上千的机器共同计算来加速这个过程,但在从一个机器拓展到一个集群时我们会遇到比原来多得多的问题。比如我们该如何并行化计算,如何把数据分发到机器中,如何处理机器宕机带来的问题,毫无疑问,这是一个复杂的问题。
分布式的计算带来了各种各样复杂的问题,但MapReduce的出现给解决分布式计算带来了一个足够简洁的解决方案。
编程模型
.png) 整个计算过程接受一组输入键值对,并输出一组键值对。我们需要为这个计算过程提供两个函数,
整个计算过程接受一组输入键值对,并输出一组键值对。我们需要为这个计算过程提供两个函数,Map和Reduce。
Map函数接受一组键值对输入并生产一组中间键值对,然后按照一定的标准把这些键值对分组并传输给Reduce函数。
Reduce函数接受中间键值对作为输入,合并这些数据并产生一组键值对作为最终输出。
一个简单的案例
下面是一个MapReduce实现的伪代码
1 | map(String key, String value): |
map函数获取文章中的每个单词,并简单的给每个key赋值为1,然后把这些结果提交给reduce函数,reduce函数合并相同的key,输出最终结果。
常见应用场景
-
Distributed Grep:在大规模文本数据中查找指定的字符串,并输出匹配的行。Map 阶段将每个输入文件分割为多个块,Reduce 阶段将匹配的行进行汇总。
-
Count of URL Access Frequency:统计 Web 日志中每个 URL 的访问频率,用于分析用户行为和网站性能。Map 阶段将每个日志文件解析为键值对,其中键为 URL,值为 1,Reduce 阶段将相同 URL 的值相加并输出。
-
Reverse Web-Link Graph:将 Web 页面之间的链接关系转化为反向的页面到链接的关系,用于搜索引擎排名等应用。Map 阶段将每个页面解析为键值对,其中键为页面 URL,值为与该页面相连的 URL,Reduce 阶段将相同 URL 的值进行合并。
-
Term-Vector per Host:为每个主机计算其包含的文本数据中每个单词的频率向量,用于文本分类和信息检索。Map 阶段将每个文档解析为键值对,其中键为主机名,值为单词和出现次数的列表,Reduce 阶段将相同主机名的列表进行合并。
-
Inverted Index:为大规模文本数据建立倒排索引,用于支持全文搜索和相关性排序等应用。Map 阶段将每个文档解析为键值对,其中键为单词,值为文档 ID 和出现次数的列表,Reduce 阶段将相同单词的列表进行合并。
-
Distributed Sort:对大规模数据进行排序,用于数据清洗、数据分析等应用。Map 阶段将输入数据分割为多个块,并对每个块进行内部排序,Reduce 阶段将多个有序块进行归并排序。
MapReduce实现
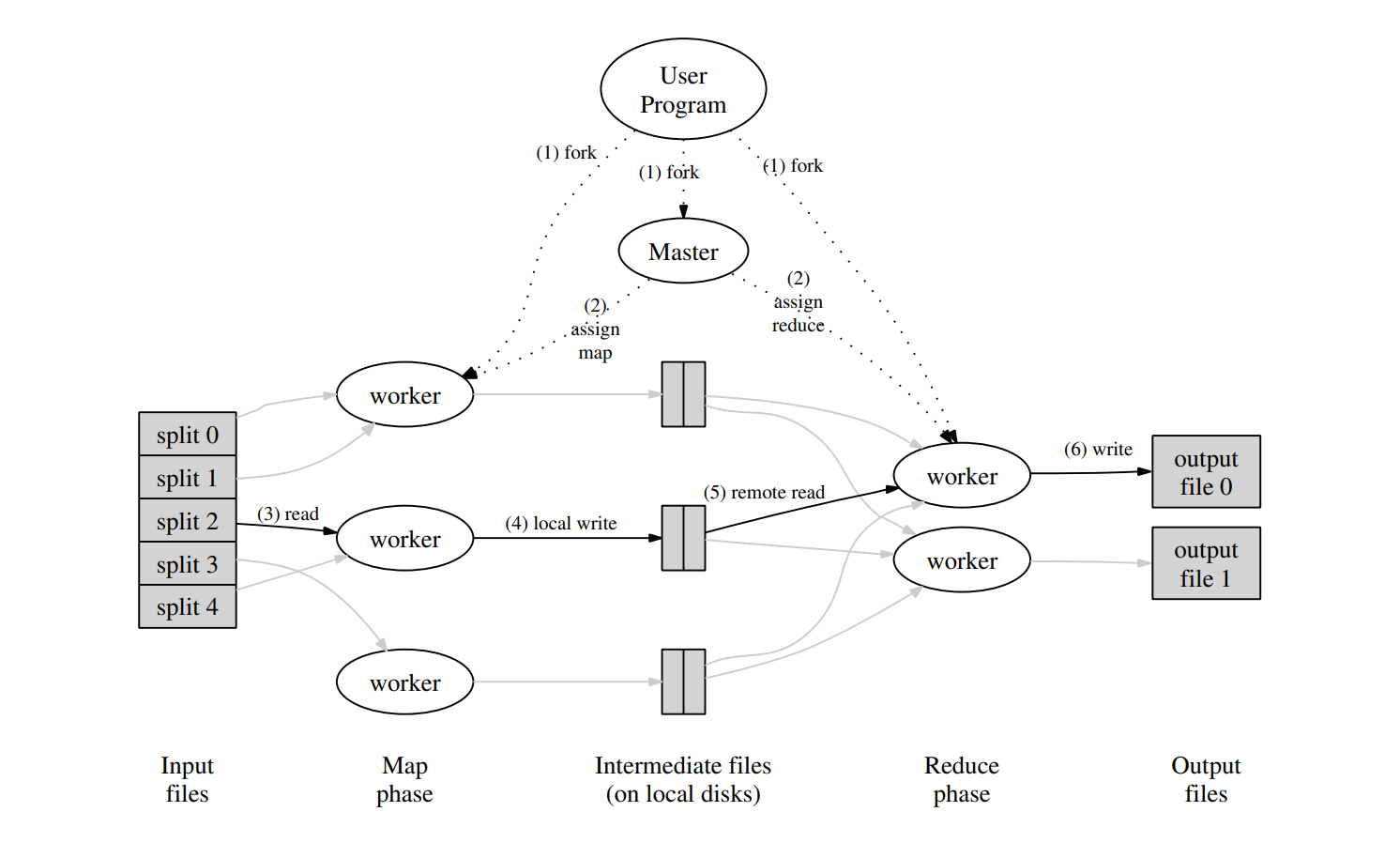
执行流程
我们把输入分成M份的split,然后分配给worker执行map,在worker执行完毕后,我们整理worker的输出的中间键值对,根据Reduce分区的数量分为R份,然后再交给Reduce函数执行。
下面是具体的流程:
- 首先我们把输入分成M份,每一份的大小通常在16~64M范围内,这由用户设置。
- 然后master节点分配未完成的任务给空闲的节点。
- 被分配到map任务的节点处理输出的键值对,并将中间键值对保存在本地缓存中。
- 然后执行map任务的节点会定期将缓存中的内容写到磁盘,并将这些内容分成R个区域,然后将它们的位置发送给master。
- 当reduce节点被通知这些文件的位置,它会通过RPC来读取文件的内容从map节点中,等reduce节点读取完所有需要的内容,它会对中间键值对进行排序。
- 然后reduce节点会迭代这些键值对,并将它们合并,最终生成一个结果文件。
- 最后当所有的任务完成,master节点会通知用户程序并返回。
在成功的结束执行以后,我们会获得R份的输出文件,一般来说,我们不需要去合并这R份文件,因为它们往往是其它分布式计算的输入或者它们可以被其它的分布式应用处理。
主节点数据结构
Master节点需要维护一些数据结构以保证整个过程的正确执行,下面是部分数据结构:
- Job 完成状态:记录每个 map 任务和 reduce 任务的完成状态,状态包括未执行,正在处理和已完成。
- 资源分配表:记录每个 worker 节点的负载状况和可用资源,以便于进行任务调度和资源分配。
- 中间结果信息表:记录每个 map 任务产生的中间结果文件的位置和大小,以便于 reduce 任务能够访问和处理中间结果。
容错
这里我们仅仅讨论Worker Failure的情况,对于Master节点的容错我们不予讨论。
首先,master节点会定时去ping工作节点,假如在一段预先设定好的时间内没有收到回复,master会认为该工作节点已经宕机,所有由该节点完成的map任务都会被设置为空闲状态,由该节点正在执行的map或reduce任务都会被设置为未完成,这些被重新设置为未完成的任务会被重新执行。
正在执行的任务需要重新执行很容易理解,这里解释一下为什么所有被该节点执行完成的map节点都需要重新执行。这是因为在MapReduce模型中,map函数执行的结果会被放在本机的本地磁盘中,而reduce函数的执行结果会被放置在远程文件系统中,如何执行map的机器宕机,那么执行的结果将无法被访问,所以必须重新执行,而reduce函数的执行结果由于保存在远程,所以无需重新执行。