
『mysql』mysql语法速记
一、数据定义
主要使用DDL,用于定义数据对象(数据库,数据表,视图,索引等)
数据库(DATABASE)
创建数据库
1 | create DATABASE test; |
删除数据库
1 | DROP DATABASE test |
选择数据库
1 | USE test; |
数据表(TABLE)
数据表的创建与删除
创建数据表
1 | CREATE TABLE user ( |
根据已有表创建
1 | CREATE TABLE viper_user AS |
删除数据表
1 | DROP TABLE user; |
修改数据表
添加列
1 | ALTER TABLE user |
删除列
1 | ALTER TABLE user |
修改列
1 | ALTER TABLE user |
添加主键
1 | ALTER TABLE user |
删除主键
1 | ALTER TABLE user |
视图(VIEW)
视图是基于SQL语句的结果集的可视化表。视图是虚拟的表,本身不储存数据,也不处理数据。主要用于简化和方便我们的操作,但是视图的操作和普通的表的操作方式类似
视图的作用
- 简化复杂的sql操作
创建视图
1 | CREATE VIEW top_10_user_view AS |
删除视图
1 | DROP VIEW top_10_user_view; |
索引(INDEX)
索引可以更加高效的查询数据。用户无法看到索引,但是可以用它来加速查询。
但是维护索引需要额外的空间和时间,所以更新一个含有索引的表花费的代价会比不含有索引的表更大,所以一般推荐是只在被频繁搜索的列上创建索引
唯一索引
表面此索引的每一个索引值都可以唯一标识表中的一个记录
创建索引
1 | CREATE INDEX user_index |
创建唯一索引
1 | CREATE UNIQUE INDEX user_index |
删除索引
1 | ALTER TABlE user |
约束
SQL 约束用于规定表中的数据规则。
- 如果存在违反约束的数据行为,行为会被约束终止。
- 约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)。
- 约束类型
NOT NULL- 指示某列不能存储 NULL 值。UNIQUE- 保证某列的每行必须有唯一的值。PRIMARY KEY- NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。FOREIGN KEY- 保证一个表中的数据匹配另一个表中的值的参照完整性。CHECK- 保证列中的值符合指定的条件。DEFAULT- 规定没有给列赋值时的默认值。
创建表时使用约束条件:
1 | CREATE TABLE Users ( |
二、增删改查
又称为CRUD,数据库基本操作
create-增delete-删update-改retrieve-查
插入数据
使用INSERT INTO
插入完整的行
1 | INSERT INTO user |
插入行的一部分
1 | INSERT INTO user(username,password,email) |
插入查询出来的数据
1 | INSERT INTO user (username) |
更新数据
使用UPDATE
更新数据
1 | UPDATE user |
删除数据
使用DELETE
删除指定数据
1 | DELETE FROM user |
删除表中所有数据
1 | TRUNCATE TABLE user; |
查询数据
SELECT- 查询DISTINCT-返回不同的值LIMIT-限制返回的行数,可以接受两个参数,第一个参数是开始查询的行数,第一行是0;第二个是返回的总行数
单列查询
1 | SELECT id FROM user; |
查询多列
1 | SELECT id,username FROM user; |
查询所有列
1 | SELECT * FROM user; |
查询不同值
1 | SELECT DISTINCT |
限制查询结构
1 | # 返回前5行 |
三、子查询
子查询是嵌套较大的查询中的一个小查询,子查询也被称为内部查询或者内部选择
- 子查询嵌套在
SELECT、UPDATE、DELETE、INSERT或者另一个子查询中 - 子查询需要用
()括起来 - 子查询优先于父查询执行,因为需要先获得子查询的结果
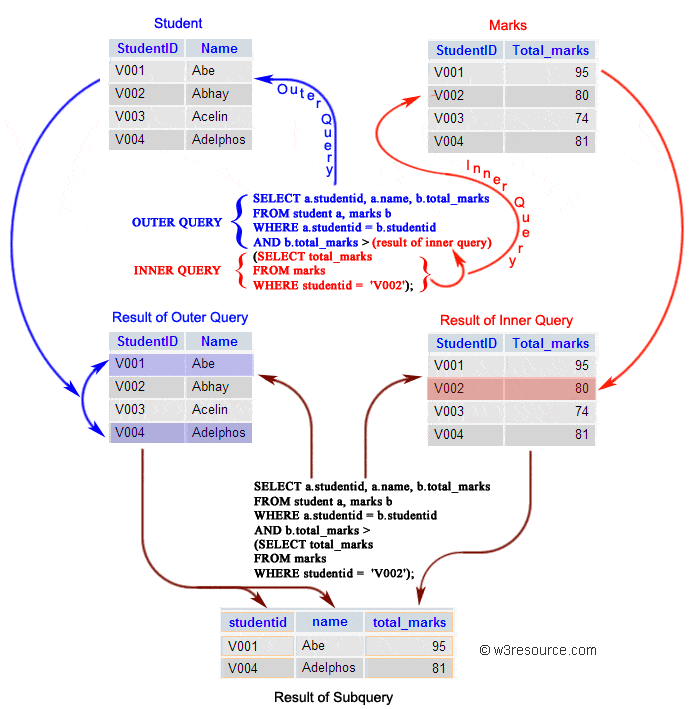
子查询中的子查询
1 | SELECT cust_name, cust_contact |
WHERE
WHERE用于过滤记录,WHERE后跟着一个true或者false的条件
可以在WHERE中使用的操作符
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
| IN | 指定针对某个列的多个可能值 |
SELECT
1 | SELECT * FROM user |
UPDATE
1 | UPDATE user |
DELETE
1 | DELETE FROM uesr |
IN和BETWEEN
IN在WHERE子句中使用,用于在记录中找到特定的值。
BETWEEN在WHERE子句中使用,用于在记录中找到特定范围的值。
IN
1 | SELECT * FROM user |
BETWEEN
1 | SELECT * FROM user |
AND、OR、NOT
三者用于对过滤条件的逻辑处理
AND
1 | SELECT * FROM user |
OR
1 | SELECT * FROM user |
NOT
1 | SELECT * FROM user |
LIKE
LIKE在WHERE子句中使用,用于确定字符串是否匹配模式,所以只有在字段是文本值的时候才可以使用。
LIKE支持两个通配符,_和%
_表示任意字符出现一次%表示任意字符出现任意次数
不要随意的使用通配符,这可能会导致你的查询非常缓慢
当我们要匹配的字符串中真的含有_和%时,我们可以使用转义字符\%和\_
%
1 | SELECT * FROM USER |
_
1 | SELECT * FROM USER |
四、连接和组合
连接(JOIN)
连接用于连接多个表,而且条件语句使用ON而不是WHERE。
连接可以替换子查询,而且效率往往比子查询效率更高。
连接分为三种类型:
- 外连接
- 左(外)连接
- 右(外)连接
- 全外连接
- 内连接
- 自连接
- 自然连接
- 全外连接(mysql不支持)
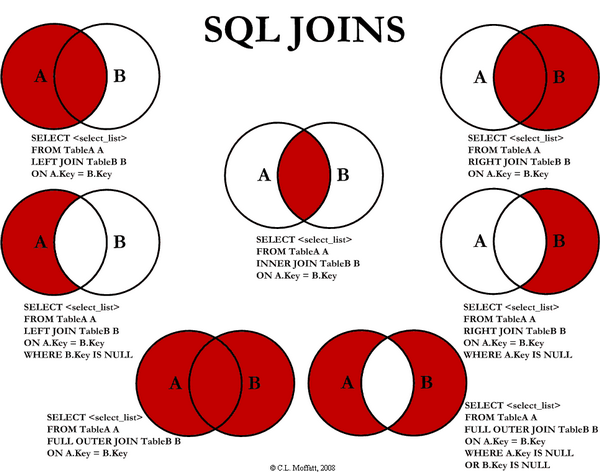
内连接(INNER JOIN)
内连接又称等值连接,默认情况下,返回表之间的公共部分,没有条件的情况下返回笛卡尔积(最好不要这样做,这样会很容易返回爆炸多的行数)
1 | SELECT * |
自连接(=)
自连接看看出内连接的一种,只是连接的是表的自身而已。
1 | SELECT c1.cust_id, c1.cust_name, c1.cust_contact |
ps:没感觉到用处
为什么不直接
1 | SELECT c1.cust_id, c1.cust_name, c1.cust_contact |
自然连接(NATURAL JOIN)
可以自动的连接同名列
1 | SELECT * FROM users |
等价于上面内连接的写法,但是内连接不同的是内连接可以自己指定列,而不需要列明相同
1 | SELECT * |
外连接(OUTER JOIN)
Mysql不支持
左连接(LEFT JOIN)
以左边的表为主,即便左边的表没有与右边的表关联也会被保留
1 | SELECT customers.cust_id, orders.order_num |
右连接(RIGHT JOIN)
与左连接相反,以右边的表为主
1 | SELECT customers.cust_id, orders.order_num |
组合(UNION)
UNION将多个结果集合并成一个并返回
基本规则:
- 所有查询的列数和列顺序必须相同
- 列的数据类型必须兼容
只能有一个ORDER BY语句,且位于语句的最后。
默认去除相同行,如需保留,使用UNION ALL。
应用场景:
- 一个查询从多个表中返回结果
- 一个表执行多个查询
1 | SELECT cust_name, cust_contact, cust_email |
JOIN vs UNION
JOIN中连接的列可能不同,但是UNION中,查询的列数和顺序必须相同JOIN把查询的列水平放置,也就是构成笛卡尔积,UNION把查询的列垂直放置
五、函数
不同数据库的函数往往不同,下面以Mysql为例
文本处理
| 函数 | 说明 |
|---|---|
LEFT()、RIGHT() |
左边或者右边的字符 |
LOWER()、UPPER() |
转换为小写或者大写 |
LTRIM()、RTIM() |
去除左边或者右边的空格 |
LENGTH() |
长度 |
SOUNDEX() |
转换为语音值 |
其中, SOUNDEX() 可以将一个字符串转换为描述其语音表示的字母数字模式。
1 | SELECT * |
日期和时间处理日期和时间处理
- 日期格式:
YYYY-MM-DD - 时间格式:
HH:MM:SS
| 函 数 | 说 明 |
|---|---|
AddDate() |
增加一个日期(天、周等) |
AddTime() |
增加一个时间(时、分等) |
CurDate() |
返回当前日期 |
CurTime() |
返回当前时间 |
Date() |
返回日期时间的日期部分 |
DateDiff() |
计算两个日期之差 |
Date_Add() |
高度灵活的日期运算函数 |
Date_Format() |
返回一个格式化的日期或时间串 |
Day() |
返回一个日期的天数部分 |
DayOfWeek() |
对于一个日期,返回对应的星期几 |
Hour() |
返回一个时间的小时部分 |
Minute() |
返回一个时间的分钟部分 |
Month() |
返回一个日期的月份部分 |
Now() |
返回当前日期和时间 |
Second() |
返回一个时间的秒部分 |
Time() |
返回一个日期时间的时间部分 |
Year() |
返回一个日期的年份部分 |
1 | mysql> SELECT NOW(); |
数值处理
| 函数 | 说明 |
|---|---|
| SIN() | 正弦 |
| COS() | 余弦 |
| TAN() | 正切 |
| ABS() | 绝对值 |
| SQRT() | 平方根 |
| MOD() | 余数 |
| EXP() | 指数 |
| PI() | 圆周率 |
| RAND() | 随机数 |
汇总
| 函 数 | 说 明 |
|---|---|
AVG() |
返回某列的平均值 |
COUNT() |
返回某列的行数 |
MAX() |
返回某列的最大值 |
MIN() |
返回某列的最小值 |
SUM() |
返回某列值之和 |
AVG() 会忽略 NULL 行。
使用 DISTINCT 可以让汇总函数值汇总不同的值。
1 | SELECT AVG(DISTINCT col1) AS avg_col |
六、排序和分组
order by
用于对结果集排序,有两种排序模式
ASC:升序(默认)DESC:降序
1 | SELECT * FROM products |
group by
把记录分组到汇总行中,为每个汇总行返回一个记录
通常配合汇总函数使用
1 | SELECT cust_name, COUNT(cust_address) AS addr_num |
所有cust_name相同的字段会被汇总成一个字段返回
HAVING
专门用于过滤汇总的组记录
1 | SELECT cust_name,COUNT(*) AS num |
七、事务处理
MYSQL默认采用隐式提交策略(autocommit),每执行一条语句就会把这条语句当成一个事务提交。
通过set autocommit=0可以关闭自动提交,这是命令针对连接的、
当我们显式的开启一个事务START TRANSACTION时,会关闭隐式提交;当COMMIT或者ROLLBACK之后会重新开启隐式提交
事务命令:
START TRANSACTION-开启一个事务SAVEPOINT-在事务中创建保存点ROLLBACK TO-回滚到某个保存点,如果没有设置则返回到START TRANSACTION的位置COMMIT-提交事务
示例:
1 | # 开启事务 |
八、权限控制
采用GRANT和REVOKE控制访问权限。
该命令可以在以下这些层次上控制访问权限:
- 整个服务器,使用
GRANT ALL和REVOKE ALL - 整个数据库,使用
ON database.*,第一个参数式数据库,第二个参数是数据表,*代表对全部表都授予权限 - 特定的表,使用
ON database.table - 特定的列
- 特定的储存过程
查询mysql中的所有用户信息
1 | USE mysql; |
创建账户
1 | CREATE user myuser INDENTIFIED BY 'mypassword'; |
修改账户名
1 | UPDATE user SET user='newuser' WHERE user='myeser'; |
查看权限
1 | SHOW GTANTS FOR myuser; |
授予权限
1 | GRANT SELECT, INSERT ON *.* TO myuser; |
删除权限
1 | REVOKE SELECT, INSERT TO *.* FROM myuser; |
更改密码
1 | SET PASSWORD FOR myuser = 'mypass'; |